 Artem Voloskovets
Artem Voloskovets

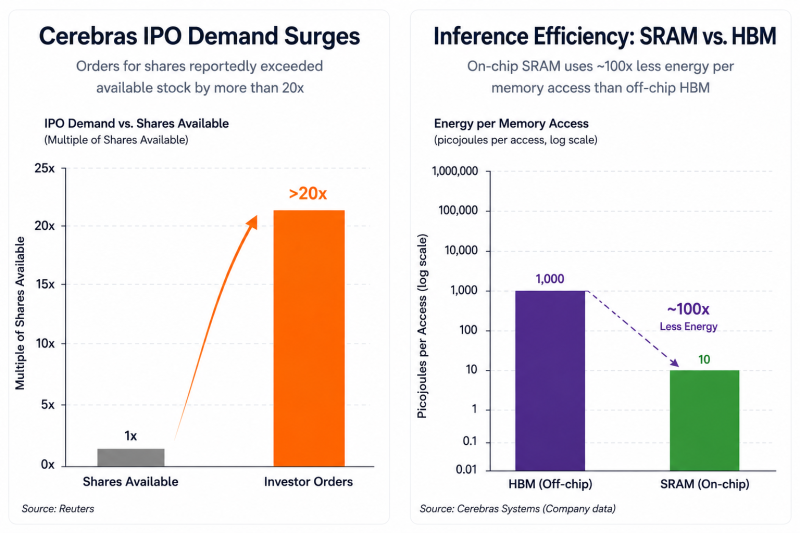
According to Reuters, orders for the AI chipmaker’s stock allegedly exceeded available shares by more than 20 times - potentially making the offering one of the largest and most aggressively demanded tech IPOs of the year.
But inside the AI infrastructure market, the excitement is not just about another chip company entering public markets. It is about a growing realization that the next bottleneck in AI may not be raw compute power - it may be energy efficiency during inference.
The AI Inference Problem Is Getting Worse
Most modern AI systems spend enormous amounts of energy moving data rather than actually computing. Traditional GPUs are increasingly constrained by memory bandwidth during inference workloads. Each generated token often requires repeatedly pulling massive model weights from high-bandwidth memory (HBM), creating a system where compute units spend much of their time waiting for data transfers.
That creates two major problems:
- rising latency,
- and exploding energy consumption.
As inference demand scales globally across chatbots, enterprise AI, autonomous systems, and edge deployments, those inefficiencies become increasingly expensive.
And that is where Cerebras is trying to differentiate itself.
Why Cerebras Is Suddenly Getting So Much Attention
Unlike traditional GPU architectures, Cerebras built its platform around a radically different concept:
One giant wafer-scale processor.
Its Wafer-Scale Engine integrates massive amounts of on-chip SRAM memory directly into the processor instead of relying heavily on external HBM. That architectural difference matters because SRAM memory accesses consume dramatically less energy than off-chip memory transfers.
In practical terms:
- less data movement,
- lower latency,
- reduced power consumption,
- and potentially far better inference efficiency at scale.
For hyperscalers and AI infrastructure providers facing rising power constraints, that value proposition is becoming increasingly important.
The Bigger Trend Behind the IPO Demand
The overwhelming interest in Cerebras suggests investors are beginning to expand the AI semiconductor narrative beyond training GPUs alone. For the past two years, markets largely rewarded companies tied to:
- AI training clusters,
- hyperscale GPU deployments,
- and raw compute scaling.
Now attention is starting to shift toward a different question:
Who can run AI models most efficiently at global scale?
That distinction could become critical as AI transitions from experimentation into mass deployment across enterprises, governments, telecom infrastructure, robotics, and consumer applications. Inference economics may ultimately matter just as much as training performance.
Why Wall Street Is Watching Closely
The IPO demand surge also reflects a broader investor search for the “next Nvidia” within the AI infrastructure stack. But Cerebras is not positioning itself as a direct GPU replacement. Instead, the company appears to be targeting one of the fastest-growing pain points in AI: how to reduce the cost, latency, and energy intensity of inference workloads. And in a world where electricity, cooling, and memory bandwidth are becoming strategic constraints for AI scaling, that narrative may become increasingly difficult for markets to ignore.
 Artem Voloskovets
Artem Voloskovets


