 Usman Salis
Usman Salis

The AI trade revolved around one idea: larger models required larger infrastructure. That dynamic fueled one of the most aggressive capital spending cycles the technology industry has ever seen. Hyperscalers poured tens of billions into GPU clusters, frontier labs raced to train larger systems and markets rewarded companies tied directly to training compute.
But a new forecast from Evercore ISI suggests the next phase of the AI economy may look very different. The firm projects annual AI token usage could exceed 4,000 quadrillion tokens by 2030, implying a massive expansion in global AI infrastructure demand over the next several years.
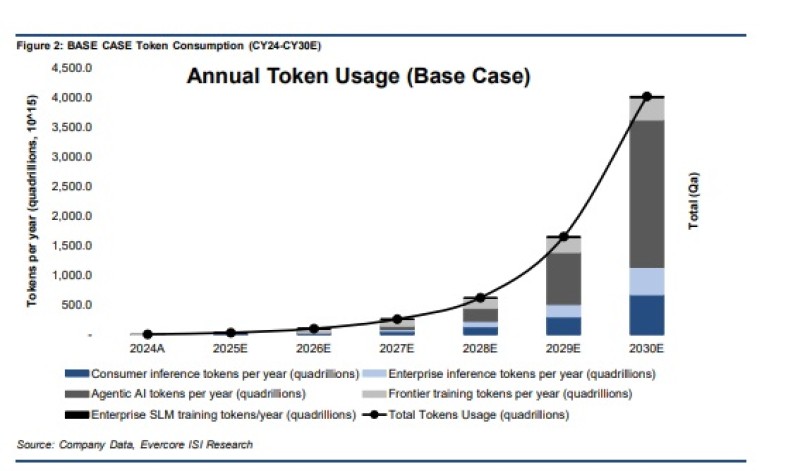
The more important signal inside the forecast is not the raw growth itself. It is the changing structure of token consumption.
The AI Market Is Shifting Toward Inference
By 2026, frontier model training is still expected to represent the majority of total token usage at roughly 59%. Consumer inference accounts for around 26%, while enterprise inference and agentic AI remain relatively small contributors.
By 2030, the mix changes dramatically.
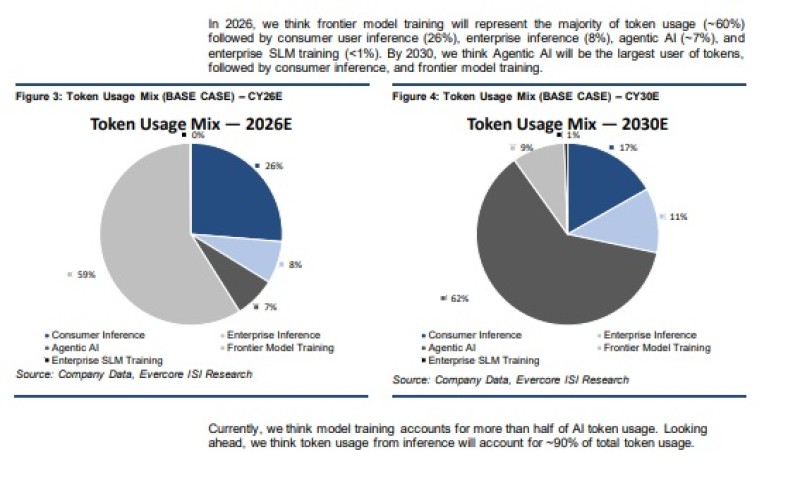
Inference-related workloads are projected to account for about 88% of total token consumption by the end of the decade, driven by enterprise deployment, consumer applications and agentic AI systems operating continuously in the background.
That transition matters because training and inference reward different parts of the AI stack. Training is centralized and capital intensive. It depends on massive compute clusters, frontier model development and hyperscaler capex cycles. Inference behaves more like infrastructure. The economics shift toward efficiency, networking, latency optimization and serving billions of requests at sustainable cost.
The market implications could be significant. The first phase of the AI boom rewarded companies supplying compute for frontier training. Nvidia became the clearest beneficiary because model scaling required increasingly large GPU deployments. Inference changes the focus.
Markets may increasingly prioritize:
- inference efficiency,
- networking infrastructure,
- enterprise deployment,
- memory optimization,
- edge AI infrastructure,
- and operational cost per token.
That creates a different competitive environment from the training race that defined the earlier phase of the AI cycle.
The Next AI Cycle May Be About Usage, Not Models
The forecast also challenges the idea that AI demand remains mostly speculative. Inference only reaches these levels if businesses and consumers actively use AI systems across software, search, automation and enterprise workflows on a continuous basis. In other words, the model assumes AI evolves from a development race into a persistent utility layer embedded across the global digital economy.
That distinction matters for markets. Training demand can remain concentrated among a relatively small number of companies. Inference requires broad adoption. It depends on real usage rather than future expectations alone. The result is a structural shift in how AI infrastructure may be valued over time.
The market spent the last two years focused on who could train the largest models fastest. The next phase may depend more on who can make AI efficient, persistent and economically scalable at global volume.
The next bottleneck may no longer be compute availability, but whether AI companies can generate enough revenue per token to justify infrastructure spending at this scale.
Training created the first Nvidia boom. Inference could help determine whether AI infrastructure remains concentrated among a small number of dominant platforms or evolves into a far more competitive market.
 Usman Salis
Usman Salis


