 Marina Lyubimova
Marina Lyubimova

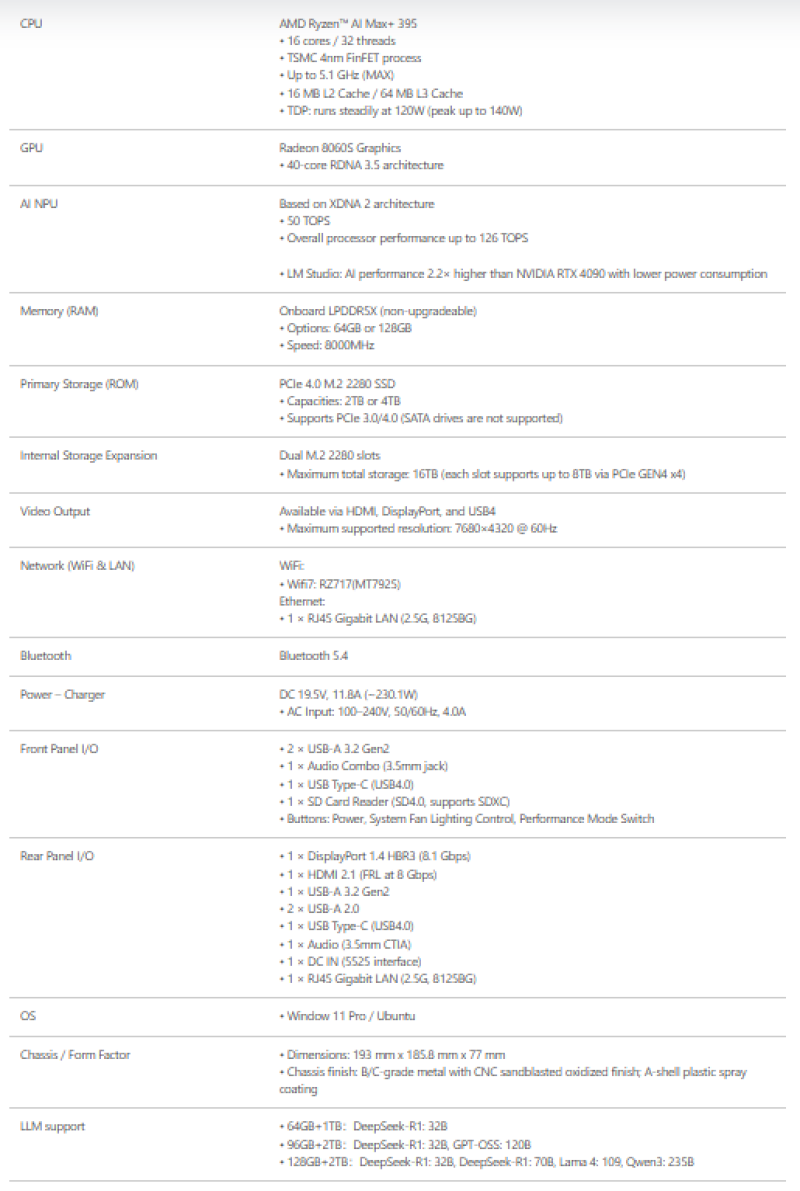
AMD is betting that memory capacity matters more. Its new Ryzen AI Max+ 395 platform combines a 16-core Zen 5 processor with up to 128GB of unified memory. According to AMD's published specifications, the system can run models as large as Qwen3-235B on a desktop-sized machine measuring just 193 × 185.8 × 77 mm.
The announcement raises a practical question: how much hardware is actually needed to run frontier-scale AI models?
Why Memory Has Become the Main Bottleneck
Most large language models hit memory limits before they hit compute limits. A model cannot run if it does not fit into available memory, regardless of how powerful the processor is. This is why developers often rely on cloud infrastructure or multiple GPUs when working with larger models.
| Hardware | Memory |
| RTX 5070 Ti | 16 GB |
| RTX 5080 | 16 GB |
| RTX 5090 | 32 GB |
| AMD AI Max+ System | 128 GB |
The gap is significant. A 128GB memory pool provides four times the capacity of an RTX 5090 and eight times the capacity of most high-end consumer GPUs.
What Models Fit Into 128GB
According to AMD's platform specifications, the 128GB configuration supports several of the largest open-source reasoning models currently available.
These include:
- DeepSeek-R1 70B
- DeepSeek-R1 120B
- GPT-OSS 120B
- Llama 4 109B
- Qwen3-235B
The last model on that list is particularly notable. Qwen3-235B is not a lightweight local model. It belongs to the same category of systems used to benchmark against OpenAI, Google, and DeepSeek.
Why AMD Chose Qwen3-235B
The model contains 235 billion parameters and uses a Mixture-of-Experts architecture that activates only a fraction of them during inference. That design allows the model to deliver stronger reasoning performance without requiring the full computational cost of a dense 235B model.
Benchmark results place it among the strongest publicly available models.
| Benchmark | Qwen3-235B | OpenAI o1 | DeepSeek-R1 | Gemini 2.5 Pro |
| ArenaHard | 95.6 | 92.1 | 93.2 | 96.4 |
| AIME 2024 | 85.7 | 74.3 | 79.8 | 92.0 |
| AIME 2025 | 81.5 | 79.2 | 70.0 | 86.7 |
| LiveCodeBench | 70.7 | 63.9 | 64.3 | 70.4 |
| CodeForces | 2056 | 1891 | 2029 | 2001 |
The results show that AMD's demo was built around a model capable of competing with leading proprietary systems in reasoning, mathematics, and coding tasks.
The Hardware Behind the System
The platform is powered by the Ryzen AI Max+ 395:
- 16 Zen 5 CPU cores
- 32 threads
- Up to 5.1 GHz boost clock
- Radeon 8060S graphics
- 40 RDNA 3.5 compute units
- 50 TOPS NPU performance
- Up to 126 TOPS total AI performance
- 55W–120W TDP
Unlike traditional AI workstations, the design relies on unified memory shared across CPU, GPU, and NPU resources. That approach reduces the need for large amounts of dedicated GPU memory, which is often the limiting factor when deploying large models locally.
What This Means for Local AI
The more interesting part of AMD's announcement is not the processor itself. It is the idea that large reasoning models are becoming constrained by memory architecture rather than raw GPU performance.
For developers, researchers, and companies running private workloads, a 128GB local system changes what can be deployed without cloud infrastructure. The remaining question is performance. AMD has demonstrated that Qwen3-235B fits and runs on the platform, but real-world adoption will depend on inference speed, responsiveness, and cost relative to GPU-based alternatives.
The Next Test
The next benchmark to watch is not model quality but tokens per second. If systems based on Ryzen AI Max+ 395 can deliver usable inference speeds with models such as Qwen3-235B, DeepSeek-R1 120B, and Llama 4 109B, local AI deployment may become a practical alternative to cloud inference for a wider range of workloads.
At that point, the discussion shifts from whether large models can run on a desktop PC to whether they still need a data center at all.
 Marina Lyubimova
Marina Lyubimova


