 Peter Smith
Peter Smith

Google's Gemini 2.5 Flash Native Audio Dialog (Thinking) just scored 92% on the Big Bench Audio dataset, setting a new record for speech-to-speech reasoning. This puts Google ahead of OpenAI's best offerings, including the GPT-4o pipeline that chains together transcription, text processing, and speech synthesis.
Why This Matters
The chart posted by Artificial Analysis trader - a respected AI benchmarking group - shows Gemini 2.5 sitting at the top with 92%, beating OpenAI's Speech-to-Speech GPT-4o pipeline (90%) and leaving earlier models like GPT Realtime (83%) in the dust. What makes this different? Gemini 2.5 reasons directly over spoken words without converting them to text first. That means fewer steps where things can go wrong and a more natural way of handling audio.
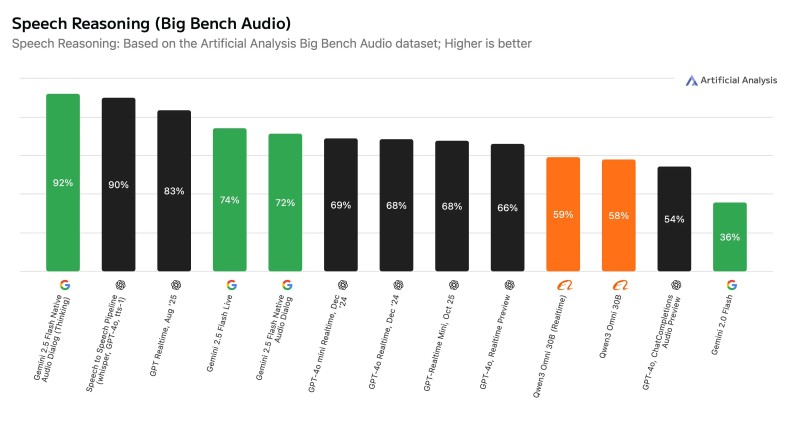
Big Bench Audio is the first benchmark built specifically to test reasoning through speech. It takes 1,000 tough questions from Big Bench Hard - a dataset known for stumping language models - and presents them as audio. It's a serious test of whether AI can actually think through what it hears.
The Speed Question
Here's the catch: Gemini 2.5's "Thinking" mode takes about 3.87 seconds before it starts responding. OpenAI's GPT Realtime models fire back in under a second. For some use cases, that delay matters. But Google also offers a non-thinking version of Gemini 2.5 that responds in just 0.63 seconds - faster than anything else out there - while still delivering solid reasoning performance.
What It Can Do
Gemini 2.5 handles audio, video, and text all at once, generating both written and spoken responses. Because it works with speech natively rather than transcribing first, it avoids the errors that pile up when models pass data through multiple stages. It also supports function calling, search grounding, and adjustable thinking depth, processes up to 128k input tokens and 8k output tokens, and has training data through January 2025.
 Peter Smith
Peter Smith


