 Eseandre Mordi
Eseandre Mordi

⬤ Fresh data on global AI compute shows a massive flip coming in how AI actually gets used. By 2030, inference work—the stuff that runs AI models in real applications—will grab roughly 75% of total AI compute demand, leaving training in the dust. Right now, training eats up most of the power, but that's changing fast as companies move from building models to actually deploying them at scale.
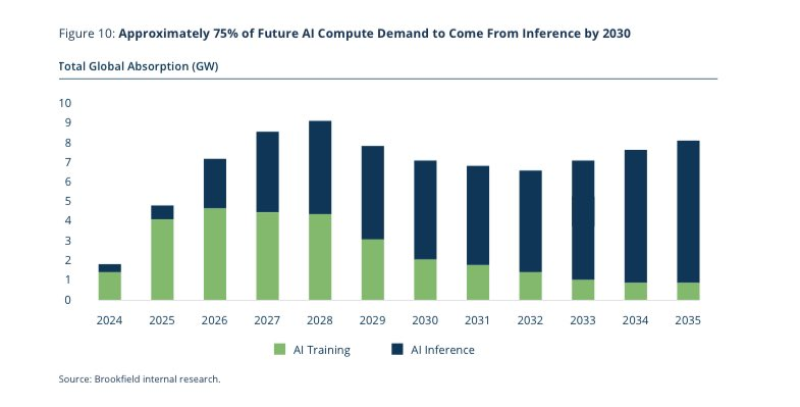
⬤ The numbers tell the story: total AI compute keeps climbing through the 2030s, measured in gigawatts. Early on, training dominates. But as the timeline rolls forward, inference starts taking over the growth curve. By the early 2030s, inference is driving most of the new demand because that's where the real-world action is—speed and efficiency matter more than raw training power when you're running millions of queries per second.
⬤ Here's where it gets interesting for chip wars. As one market observer noted: "Nvidia chips have been optimized for training, AMD is focusing on inference with higher memory capacity per chip—reducing latency by running larger models across fewer chips." That memory advantage could matter big time as inference becomes the main game.
⬤ This isn't just technical trivia—it's reshaping the entire semiconductor battlefield. When inference becomes three-quarters of the pie, chip design pivots hard toward memory bandwidth, power efficiency, and low latency instead of pure training horsepower. AMD's bet on inference-friendly architecture might look smarter as deployment scales up, while Nvidia's training dominance becomes less of a lock. The companies that nail inference economics could end up controlling the next phase of AI infrastructure.
 Eseandre Mordi
Eseandre Mordi


