 Usman Salis
Usman Salis

Here's something that caught everyone off guard: GPT-5 actually used less total compute power than GPT-4.5. That sounds backwards, right?
Efficiency Beats Brute Force
According to Epoch AI, who track AI economics religiously, OpenAI made a deliberate choice to focus on post-training refinement instead of just throwing more raw computing power at the problem.
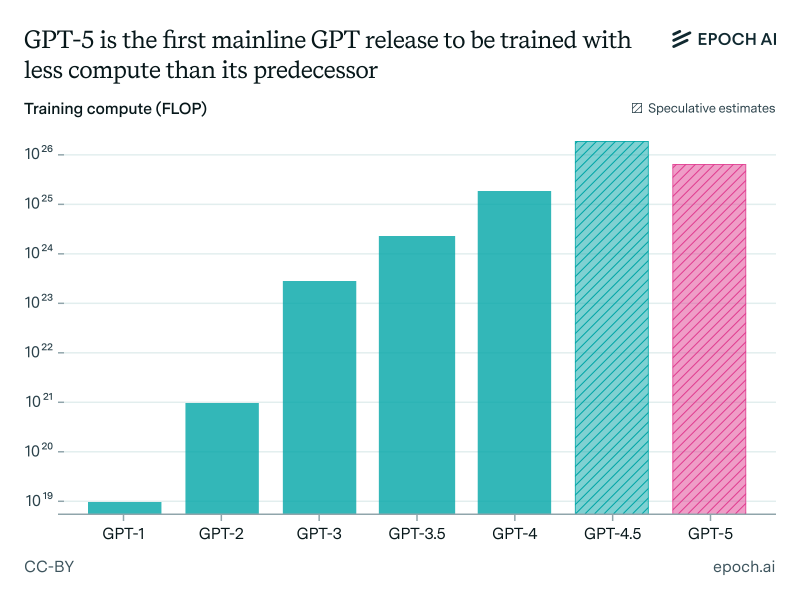
For years, AI development followed a simple rule: bigger models with more compute always won. GPT-3 and GPT-4 proved this over and over. But GPT-5 breaks that pattern completely.
OpenAI started with a smaller base model and pumped massive resources into post-training instead. We're talking reinforcement learning from human feedback, instruction tuning, safety fine-tuning - all the stuff that happens after the basic training. Turns out, each dollar spent on post-training now delivers way more bang for your buck than just scaling up.
Why Post-Training Now Rules
Here's the thing about pretraining versus post-training: pretraining gives models their general knowledge, but post-training makes them actually useful. OpenAI's heavy focus on fine-tuning GPT-5 created improvements in three key areas:
- Instruction following - it gets what you're asking for, even with complex prompts
- Safety alignment - way less chance of problematic outputs
- Practical performance - better at coding, reasoning, and real-world tasks
That's why GPT-5 feels more advanced despite using fewer computational resources overall.
This isn't just OpenAI being clever - it's reflecting where the whole industry is heading. Anthropic's Claude and Google's Gemini are doing similar things, focusing on alignment over raw size. The question has shifted from "how big can we go?" to "how smart can we make what we've got?"
Two major implications here. First, efficiency becomes king - smaller, cheaper models might compete with giants if they're fine-tuned right. Second, this could democratize powerful AI since you don't need exponentially more compute anymore.
 Usman Salis
Usman Salis


