 Usman Salis
Usman Salis

For years, AI development has operated on a simple principle: scale up and performance follows. Labs have poured resources into building ever-larger language models, assuming size correlates directly with capability. But recent findings from Qwen's reinforcement learning experiments suggest this relationship isn't so straightforward. As researcher Joan Cabezas highlighted on social media, smaller models can achieve remarkable performance gains through strategic training, while their larger counterparts hit a ceiling of diminishing returns.
What the Research Revealed
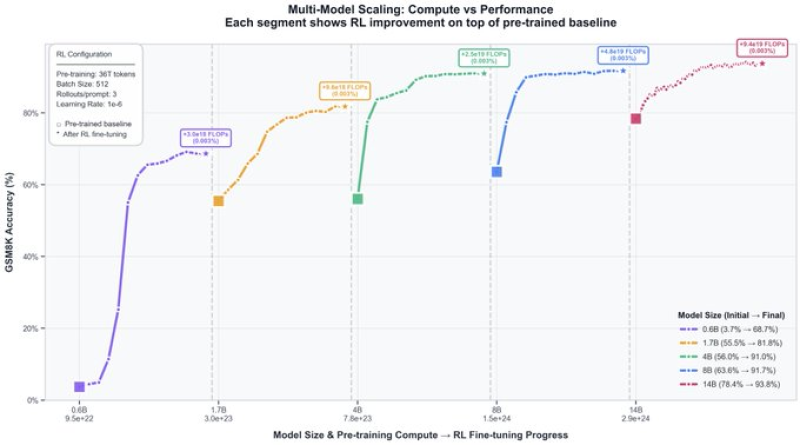
The Qwen team put five models through their paces on the GSM8K mathematical reasoning benchmark. These models ranged from a compact 0.6 billion parameters up to a substantial 14 billion. Each underwent standard pre-training before being refined with reinforcement learning.
The pattern that emerged was unexpected: the smallest model skyrocketed from roughly 38% accuracy to nearly 89% after RL training, while the largest model crept from 75% to just under 94%. The mid-sized models told a similar story, with gains tapering off as model size increased. What stands out isn't just the raw numbers, but the efficiency of improvement. A tiny model gained over 50 percentage points, while the giant gained less than 20.
Why This Changes the Game
These results flip conventional wisdom on its head. Instead of defaulting to massive models as the solution to every AI challenge, developers now have evidence that smarter training strategies might matter more than brute-force scaling. The implications ripple across the industry. Smaller models trained with reinforcement learning could deliver comparable performance at a fraction of the computational cost, making advanced AI accessible to teams without supercomputer budgets.
The timing of when to shift from pre-training to RL emerges as a critical decision point, not just an afterthought. This approach could democratize AI development, allowing researchers with limited resources to compete with tech giants.
 Usman Salis
Usman Salis


