 Saad Ullah
Saad Ullah

● In what Aadit Sheth calls a major milestone, Perplexity AI published their first scientific paper on RDMA communication for LLM systems. The paper introduces TransferEngine, a new way to handle data transfer in massive AI deployments that's already catching attention from NVIDIA and AWS.

● The core problem they solved? Getting GPUs to talk to each other efficiently has been a mess. Until now, NVIDIA's ConnectX and AWS's Elastic Fabric Adapter didn't play nice together, forcing developers to rebuild their systems for each platform. TransferEngine fixes this with a unified layer that delivers blazing-fast speeds (up to 400 Gbps) while working everywhere.
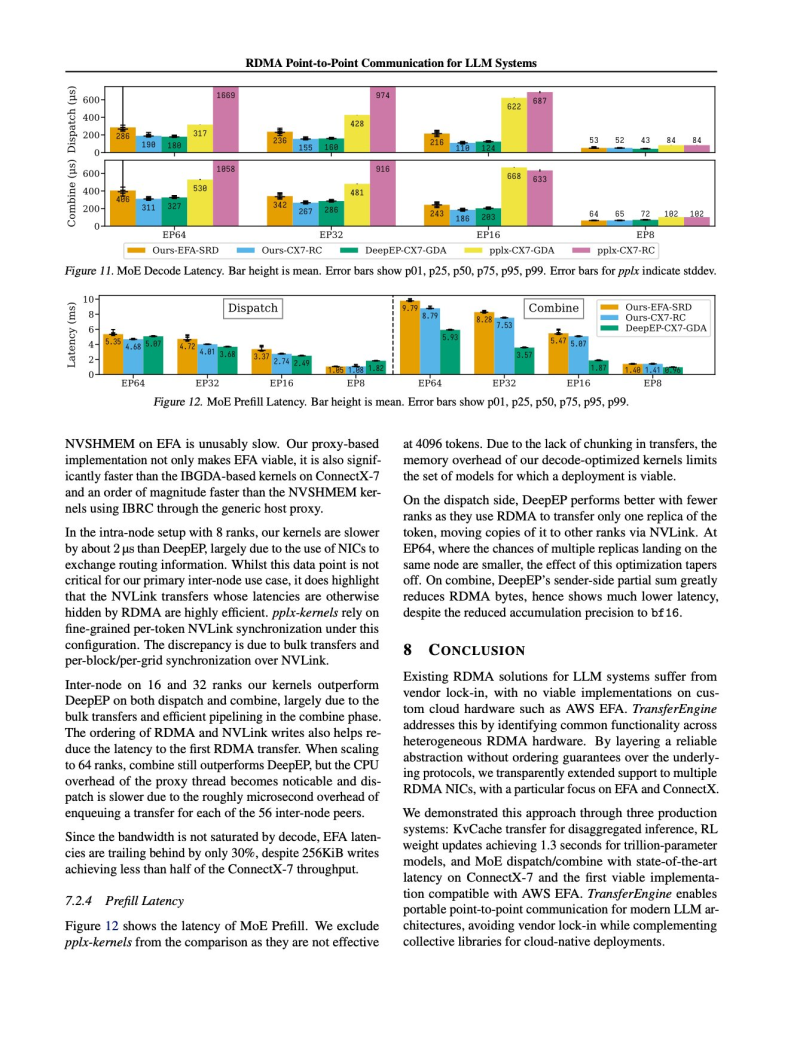
● This matters because it makes trillion-parameter models actually usable on regular cloud infrastructure — no custom hardware needed. The framework also beats DeepSeek's previous benchmark, showing lower latency across the board. For companies running large AI models, this means real cost savings and better performance.
● The researchers demonstrated three killer features: better memory handling for distributed inference, 1.3-second faster updates per trillion parameters in reinforcement learning, and sub-millisecond optimization for mixture-of-experts models.
 Saad Ullah
Saad Ullah


