 Eseandre Mordi
Eseandre Mordi

⬤ NVIDIA just dropped some eye-opening performance numbers for its Blackwell GB200 NVL72 system—we're talking about a roughly 90% cut in cost per token versus the previous H200 platform. The secret sauce? Processing up to ten times more tokens in the same timeframe while keeping power consumption steady, which directly tackles one of the biggest headaches in modern AI inference costs.
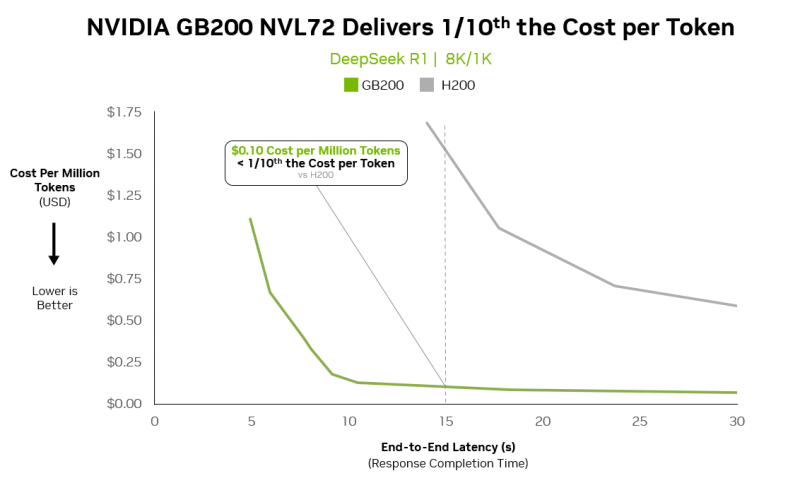
⬤ Looking at the performance data, there's a massive gap between the new Blackwell GB200 and the H200. At around 15 seconds of response time, the GB200 NVL72 hits approximately $0.10 per million tokens—genuinely less than one-tenth what H200 delivers. These benchmarks come from real-world DeepSeek R1 workloads using 8K input and 1K output configurations, not some cherry-picked synthetic test.
By executing substantially more tokens in parallel, the Blackwell NVL72 system spreads power and infrastructure costs across a much larger volume of inference work.
⬤ What's driving this dramatic cost reduction? Pure throughput muscle rather than small efficiency tweaks. The Blackwell NVL72 system cranks out way more tokens simultaneously, spreading infrastructure and power costs across significantly higher output volumes. This architecture particularly shines with mixture-of-experts models, which activate specific parameter subsets per request and thrive on high bandwidth and parallel execution.
⬤ These cost improvements matter beyond just benchmark bragging rights. As generative AI models keep expanding and moving into everyday applications, inference economics increasingly decide which products actually make it to market at scale. NVIDIA's positioning Blackwell NVL72 as the bridge that makes frontier AI models economically viable for mainstream deployment, helping transition advanced mixture-of-experts architectures from experimental labs into real production environments.
 Eseandre Mordi
Eseandre Mordi


