 Saad Ullah
Saad Ullah

Artificial intelligence continues to advance at breakneck speed, and how large language models retrieve and use information is being fundamentally rethought. For years, Retrieval-Augmented Generation (RAG) has been the go-to method for building smarter AI systems, but it's far from perfect. The main issues? Too much irrelevant information, skyrocketing compute costs, and sluggish response times. Meta AI's REFRAG aims to fix all of that by making retrieval leaner, faster, and dramatically more efficient.
The Problem with Traditional RAG
AI researcher Avi Chawla recently highlighted Meta's breakthrough, noting that REFRAG not only improves efficiency but also outperforms LLaMA across 16 different benchmarks.
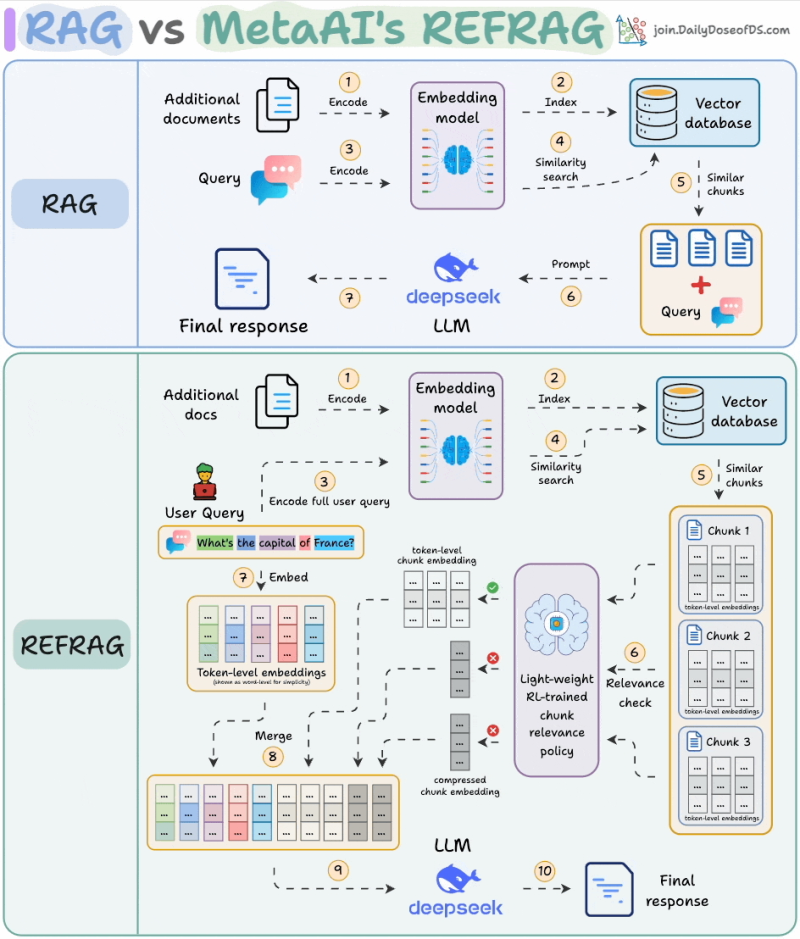
Traditional RAG systems work by connecting language models to external knowledge bases, which helps improve accuracy. But there's a catch. These systems often pull in way too much irrelevant information, forcing models to wade through unnecessary tokens. This bloats context windows, increases latency, and drives up costs. The end result is a system that's expensive to run and slower than it needs to be—hardly ideal when you're trying to scale AI applications.
How REFRAG Changes the Game
Meta's approach is elegant in its simplicity. Instead of throwing everything at the language model and hoping for the best, REFRAG uses three key techniques:
- Chunk Compression: Each piece of retrieved text gets compressed into a single embedding rather than being sent token-by-token
- Relevance Filtering: A lightweight model trained through reinforcement learning decides which chunks actually matter for answering the query
- Selective Expansion: Only the relevant chunks get expanded back into full detail, while irrelevant ones stay compressed as tiny placeholders
The result is that the language model only processes what's actually useful, cutting through the noise without sacrificing the quality of its answers.
What the Numbers Show
The performance gains are frankly remarkable. REFRAG achieves 30.85x faster time-to-first-token, meaning responses feel nearly instantaneous. Context windows expand by 16x, allowing the system to reason across much larger documents. Token usage drops by 2-4x, slashing operational costs. And perhaps most impressively, all of this happens without any loss in accuracy across summarization tasks, retrieval-augmented generation, or multi-turn conversations. These aren't minor tweaks—they represent a fundamental improvement in how these systems can operate.
Why This Matters
The implications extend well beyond raw performance metrics. Businesses suddenly have a path to running sophisticated AI systems at a fraction of the cost. Developers can build applications that handle far more complex contexts without running into technical or financial walls. And for researchers, REFRAG proves that clever architecture can beat simply throwing more compute power at a problem. This fits into a broader shift in the AI industry away from the "bigger is always better" mentality toward building systems that are genuinely smarter and more efficient.
 Saad Ullah
Saad Ullah


