 Saad Ullah
Saad Ullah

AI systems are growing more capable, but their security vulnerabilities run deeper than most safety teams realized. A recent study co-authored by OpenAI, Anthropic, Google DeepMind, and leading academic institutions exposes a troubling reality: nearly every current defense mechanism protecting large language models from jailbreaks and prompt injections can be broken by attackers who adapt their approach.
The Problem with Static Testing
The research, brought to attention by JundeWu, challenges the AI industry's assumptions about its security infrastructure and forces difficult questions about how we evaluate and protect AI systems deployed in the real world.

The research team put 12 cutting-edge LLM defense systems through rigorous testing across four categories: prompt-based defenses like Spotlighting and Prompt Sandwiching, training-based methods including Circuit Breakers and StruQ, filter models such as Protect AI and PromptGuard, and secret-knowledge approaches like Data Sentinel and MELON.
What they found was alarming. Prompt defenses that seemed effective in standard tests saw attack success rates jump to 95-99% when facing adaptive adversaries. Training-based defenses, previously considered robust with failure rates below 5%, collapsed entirely with success rates reaching 96-100%. Filter models fared no better—Protect AI, PromptGuard, and Model Armor all failed more than 90% of the time, while even the stronger PIGuard was breached in 71% of attempts. Secret defenses also crumbled, with Data Sentinel compromised over 80% of the time and MELON's vulnerability rising from 76% to 95% once attackers figured out the hidden mechanisms. Not a single defense survived adaptive testing intact.
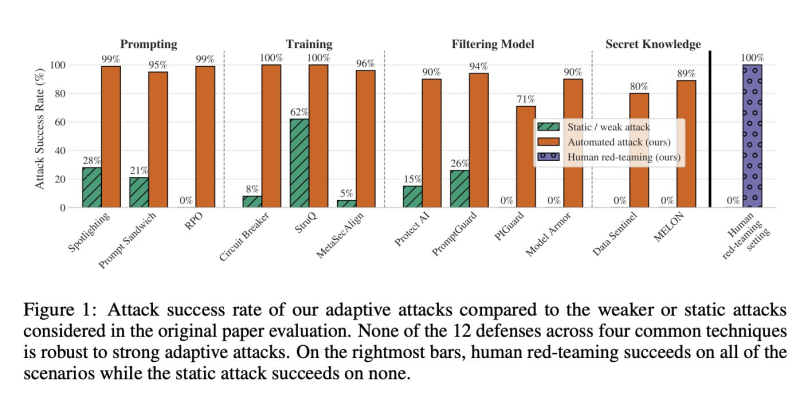
How Attackers Actually Work
The breakthrough came from the researchers' General Adaptive Attack Framework, or GAAF. Unlike traditional security tests that throw static attacks at defenses, GAAF mimics how real adversaries operate—they probe, learn, adjust, and try again.
The framework cycles through proposing attacks, measuring what works, selecting promising approaches, and refining them iteratively using techniques like gradient descent, reinforcement learning, random search, and even human feedback. This adaptive approach mirrors actual attacker behavior and proved devastatingly effective against defenses that looked solid on paper.
What This Means
For months, AI companies have pointed to prompt guards and adversarial training as evidence that jailbreak risks are manageable. This study demolishes that narrative. When tested against adaptive conditions that reflect real threats, those defenses fail comprehensively. Regulators will need entirely new frameworks for evaluating AI robustness.
Developers will have to move beyond static filters toward continuous retraining and dynamic monitoring systems. Policy discussions around safe AI deployment are about to get more intense as the evidence mounts that current safety measures create false confidence rather than real protection. The researchers put it bluntly: if a defense breaks under a single adaptive attack cycle, it's not robust.
Industry Reckoning
This rare consensus among top AI labs signals a turning point. Some experts say the findings strengthen arguments for mandatory independent red-teaming before any deployment. Others worry that stricter requirements could slow smaller players and concentrate AI power even more in the hands of major labs. Either way, the era of trusting static defenses is over. AI systems need security architectures built for adversaries who learn and adapt—because that's exactly what they're facing in the real world.
 Saad Ullah
Saad Ullah


