 Saad Ullah
Saad Ullah

AI development is reaching a turning point with GAIN-RL, a training method that teaches large language models more efficiently by focusing on the most valuable data first. With compute costs being one of the biggest obstacles to innovation, this approach could transform how quickly and affordably we can build advanced AI systems.
Smarter Fine-Tuning Through Intelligent Data Selection
A recent announcement from DeepLearning.AI introduced GAIN-RL, a reinforcement learning framework that fine-tunes language models by prioritizing high-impact examples. Rather than treating all training data the same way, the method uses the model's internal signals to figure out which samples actually drive learning forward.
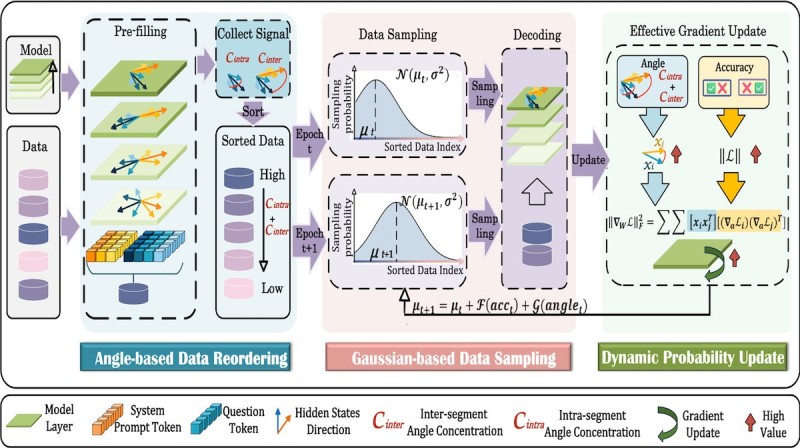
The process works through three core mechanisms: angle-based data reordering that ranks training examples by their intra - and inter-segment angle concentration, Gaussian-based sampling that emphasizes higher-value data points instead of random selection, and dynamic probability updates that adjust sampling in real-time based on accuracy and gradient effectiveness.
Real-World Performance Gains
Tests on Qwen 2.5 and Llama 3.2 delivered impressive results. GAIN-RL hit baseline accuracy in just 70 to 80 epochs, while standard methods needed 200 epochs to reach the same point. That's roughly 2.5 times faster, which means significantly lower time and compute requirements.
What This Means for the Field
The impact goes beyond just speed. Companies dealing with expensive GPU-heavy training can cut costs substantially. Researchers and developers get faster iteration cycles, letting them test ideas and refine models more rapidly. There's also an environmental angle - less compute means lower energy consumption overall.
 Saad Ullah
Saad Ullah


