 Saad Ullah
Saad Ullah

AI researcher You Jiacheng just dropped details that could change how we think about building language models. DeepSeek's latest experiment ditches the old NSA (Nested Sequence Attention) system for something radically simpler - a compact FP8 indexer that cuts attention costs by up to 9x. The diagram he shared shows exactly how their Lightning Indexer and Top-k Selector work with MLA to cherry-pick only the most important data, skipping everything else.
The Engineering Behind the Breakthrough
DeepSeek made two critical choices. First, they shrunk the indexer from 576 dimensions down to just 128 - but here's the clever part: this smaller indexer doesn't carry value vectors at all. It's purely a fast lookup tool. Second, they switched from FP16 to FP8 precision for the indexer itself. Do the math and you get 64/576, which is exactly one-ninth the original cost. The beauty is they're only cutting corners where it doesn't hurt quality. The core attention still runs at full precision on the entries that actually matter.
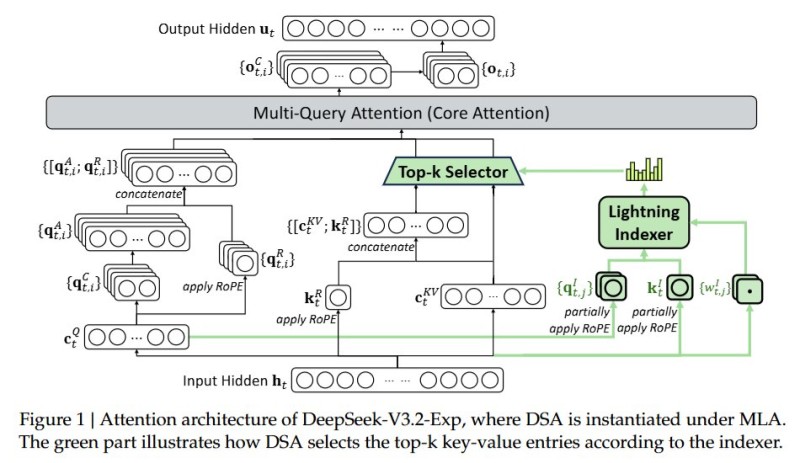
Here's how the system flows: the input hits the Lightning Indexer first, which generates compact keys using FP8. The Top-k Selector then grabs only the most relevant entries. Finally, the Multi-Query Attention module processes those selected entries with FP16 precision, keeping accuracy intact while the indexer does the heavy lifting cheaply.
Why This Actually Matters
This isn't just some academic exercise in optimization. Lower training costs mean labs can push boundaries without burning through budgets. Faster inference opens doors to real-time assistants and models that actually run on your phone instead of some distant server farm. And the FP8 approach plays perfectly with what NVIDIA and AMD are already optimizing their latest GPUs for. DeepSeek's basically saying the quiet part out loud: throwing more parameters at problems isn't the only path forward anymore.
 Saad Ullah
Saad Ullah


