 Editorial staff
Editorial staff
- Marking A Pivot Point In Digital Content History
- Breaking The Silence With Native Audio Synthesis
- How Simultaneous Processing Creates Sensory Realism
- Solving The Identity Crisis In Narrative Storytelling
- Executing A Director Level Workflow For Professional Results
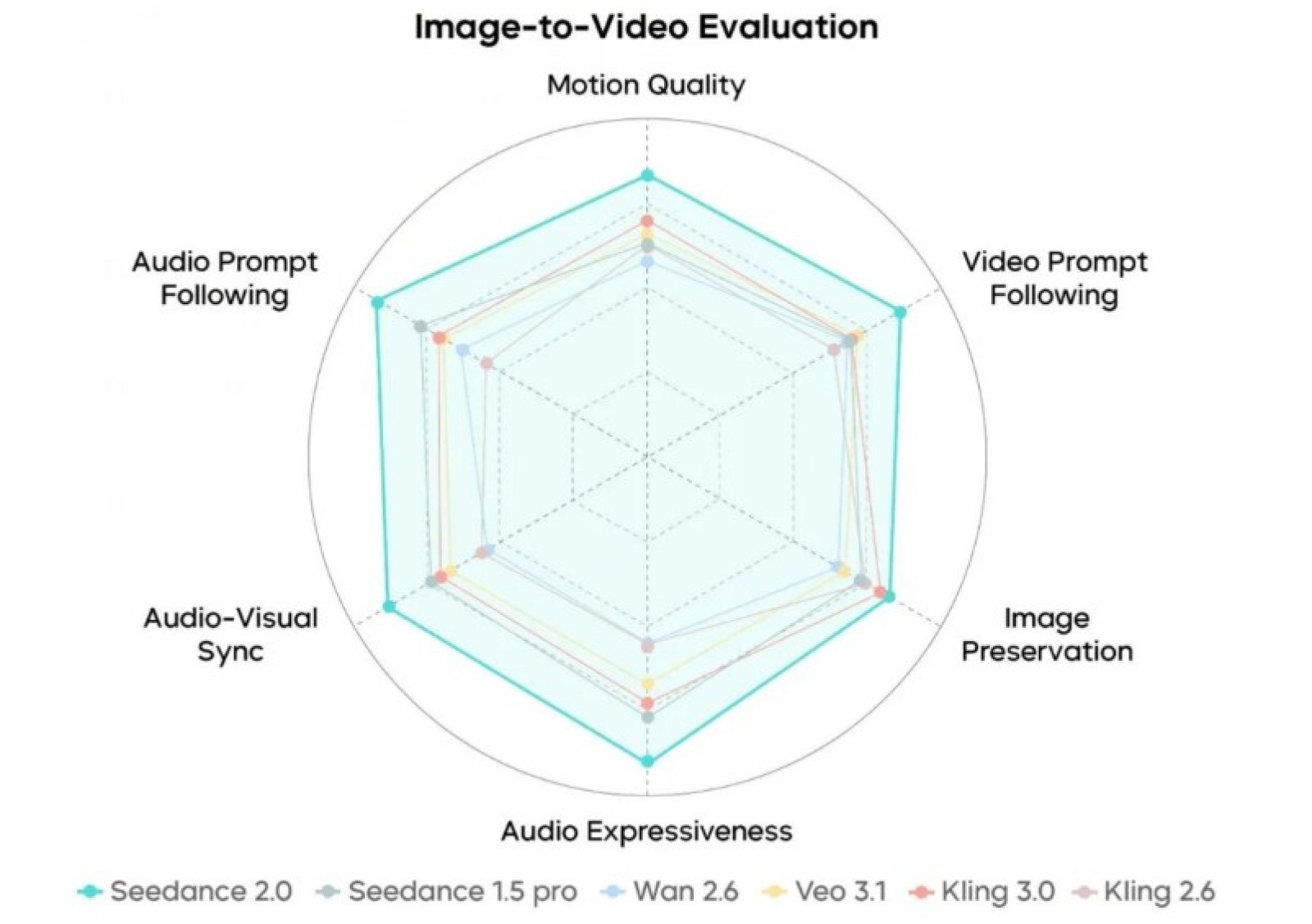
- Contrasting The New Standard Against Legacy Models
- Navigating The Realities Of A Rapidly Evolving Tool
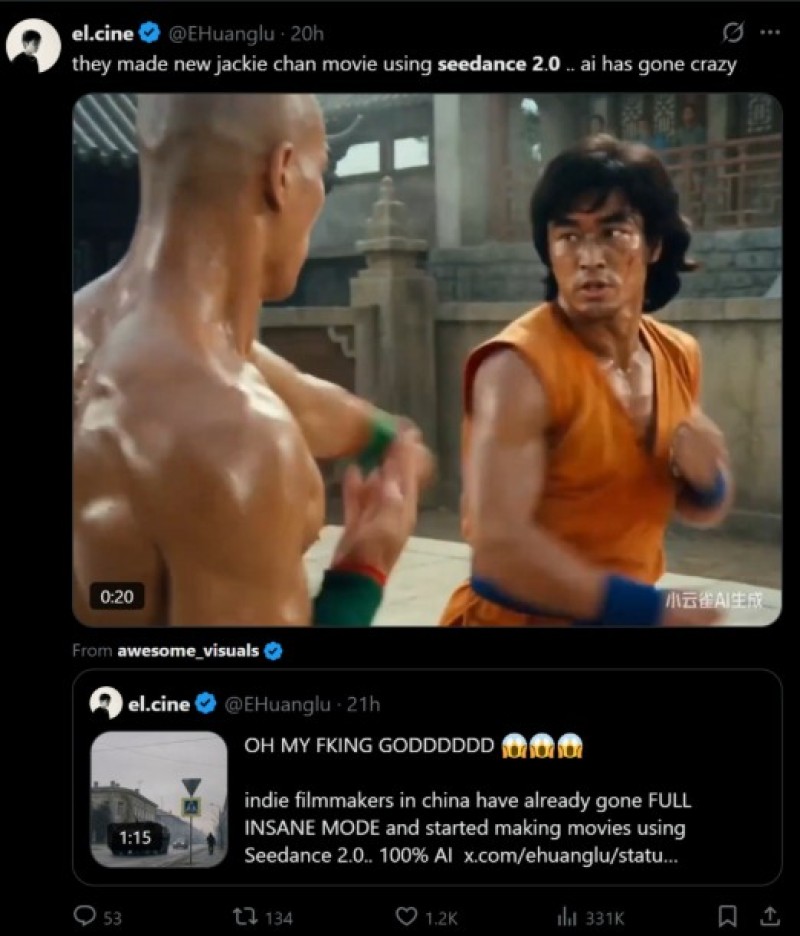
The promise of artificial intelligence in filmmaking has always been tempered by its unpredictability. For years, creators have treated these tools like slot machines—pulling the lever with a prompt and hoping for a lucky result. However, the landscape shifted fundamentally in February 2026. With the official release of Seedance 2.0 on February 12, ByteDance signaled the end of the experimental phase and the beginning of the professional era. This model does not just generate moving images; it directs scenes with a level of coherence and sensory completeness that was previously impossible without a full production crew.
Marking A Pivot Point In Digital Content History
To understand why this specific release has generated such intense industry discussion—drawing comments from tech leaders about the terrifying speed of progress—one must look at the timeline. Prior to February 2026, AI video was characterized by short, silent loops and "dream logic" where objects morphed randomly.
The introduction of this model changed the benchmark overnight. It is the first widely available system to successfully integrate "Multi-Modal Input" with "Native Audio-Visual Synchronization" in a single commercial package. This means the tool is no longer guessing; it is interpreting complex instructions involving text, image, audio, and video references simultaneously to construct a reality that obeys the laws of physics and sound.
Breaking The Silence With Native Audio Synthesis
The most audible differentiator of this technology is, paradoxically, sound. Before this update, the standard workflow involved generating a mute video and then laboriously finding stock audio to match it. This model synthesizes audio waveforms in parallel with pixel generation.
How Simultaneous Processing Creates Sensory Realism
If a user prompts a scene of a ceramic vase shattering, the system calculates the visual physics of the debris field and the acoustic frequency of the crash at the exact same millisecond. This "Native Audio" capability covers everything from environmental ambience (wind, rain) to specific foley effects (footsteps, engine revs), effectively removing an entire stage of post-production.
Solving The Identity Crisis In Narrative Storytelling
The second critical breakthrough is the stabilization of character identity. Known as the "Multi-Shot Narrative" capability, this feature addresses the "identity drift" that plagued earlier models. In previous iterations, a character might look different every time the camera angle changed. This architecture utilizes a persistent 3D understanding of the subject, allowing directors to film the same actor in a wide shot, a close-up, and a profile view without them morphing into a different person. This consistency is what transforms a series of clips into a coherent story.
Executing A Director Level Workflow For Professional Results
The user experience has been refined to match the logic of a film set. Instead of a simple text box, the interface guides the creator through a structured production pipeline. Based on the official operational capabilities, the process unfolds in four distinct stages.
Defining The Scene With Multi Modal References
The "Describe Vision" phase is now a comprehensive briefing room. Users provide detailed text scripts but can also upload reference images or existing video clips to establish the visual style. This "Style Transfer" capability ensures that the lighting and color grading match the creator's specific aesthetic requirements rather than a generic AI look.
Configuring Technical Specifications For Broadcast
In the "Configure Parameters" step, the focus shifts to distribution. The model supports native 1080p output, a requirement for any serious commercial work. Users select aspect ratios ranging from the cinematic 21:9 to the mobile-first 9:16. While native clips are generated in 5 to 12-second bursts, the system is engineered to sequence these into fluid narratives up to 60 seconds.
Synthesizing Coherent Physics And Sound
The "AI Processing" stage is where the heavy lifting occurs. The Diffusion Transformer architecture works to align the temporal coherence of the video with the synthesized audio track. This is where the model distinguishes itself from competitors, as it refuses to "hallucinate" impossible physics, instead adhering to a strict internal logic of gravity and light transport.
Exporting Production Ready Assets
Finally, the "Export & Share" step delivers a clean, watermark-free MP4 file. Because the audio and video are generated as a single unit, there is no need for synchronization in post. The file is ready to be dropped into an editing timeline or published directly to platforms like TikTok or YouTube.
Contrasting The New Standard Against Legacy Models
To visualize the leap that occurred in February 2026, it is helpful to compare the capabilities of this new architecture against the standard tools that dominated the market just weeks prior.
| Feature Domain | Pre-February 2026 Models | Seedance 2.0 (Post-Launch) |
| Audio Capability | Silent; required external foley | Native, frame-synced audio generation. |
| Character Stability | High drift; identity loss between shots. | Persistent identity across multi-shot scenes. |
| Camera Logic | Random movement; ignored lens physics | Director-level control over lens and motion. |
| Input Flexibility | Text-only or Image-to-Video | Text, Image, Audio, and Video mixed inputs. |
| Production Speed | Fast generation of unusable clips. | Slower generation of production-ready assets. |
Understanding The Strategic Value For Creators
The release of this tool represents a democratization of high-end production value. Small teams and independent creators can now generate content that visually and sonically rivals big-budget productions. The barrier is no longer access to equipment or a sound stage; it is simply the ability to imagine a scene and describe it with precision.

While the "February Leap" was significant, users must remain realistic. The model's adherence to physics is vastly improved but not perfect; complex interactions between multiple dynamic objects can still result in minor clipping. Furthermore, the sheer computational power required to generate 1080p video with synchronized audio means that "instant" generation is a misnomer—quality takes time.
However, the trajectory is clear. With this release, the conversation has moved from "Look at this cool AI trick" to "How do we integrate this into our production pipeline?" For professionals, the childhood of generative video is officially over.
 Editorial staff
Editorial staff


