 Usman Salis
Usman Salis

● Meta just published research that could change how we think about scaling reinforcement learning for large language models. As Deedy pointed out, the study reveals an "RL recipe" backed by over 400,000 GPU hours of compute, proposing the field's first systematic scaling law for RL performance—something we've long had for pretraining but not for reinforcement learning.
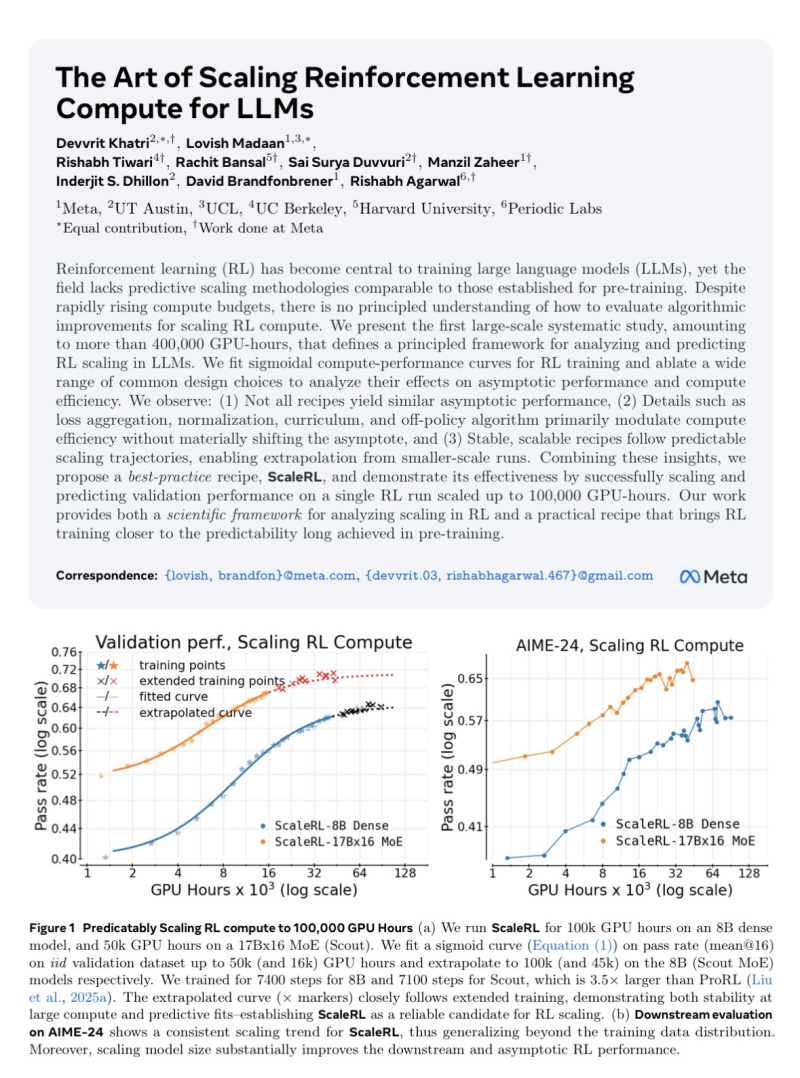
● The stakes here are real. Without clear scaling principles, companies risk burning through resources on inefficient training runs, and talented researchers might gravitate toward firms that already figured out the secret sauce. Meta's framework aims to give everyone a reproducible playbook, lowering the barriers to entry. For companies trying to apply these insights in real-world systems, partnering with an experienced LLM optimization agency can help streamline performance and deployment
● Financially, this matters too. RL compute costs have been unpredictable, making budgeting a nightmare. ScaleRL shows that RL models follow a sigmoid curve—meaning you can actually forecast what you'll get from additional compute. That makes planning more realistic and could shift how businesses and governments think about funding AI development.
● The ripple effects go beyond corporate balance sheets. As RL scaling becomes more efficient, AI adoption will likely speed up, pushing economies toward compute-heavy models rather than labor-intensive ones. This could shrink wage tax revenue while boosting profit taxes, adding fuel to debates about updating corporate tax policy in an age of automation.
● By making RL scaling predictable, Meta has brought it closer to the reliability of pretraining—potentially reshaping AI economics and sparking fresh policy conversations about how to tax and support the next generation of large-scale AI innovation.
 Usman Salis
Usman Salis


