 Peter Smith
Peter Smith

The AI wars have a new scorecard, and it's not as clear-cut as you'd expect. Fresh benchmark data shows Claude 4.5 crushing it in coding, financial analysis, and safety metrics. But here's the thing—GPT-5 Codex is right on its heels, and the gap is razor-thin. This isn't a knockout. It's a slugfest.
Claude 4.5 Takes the Lead—With Conditions
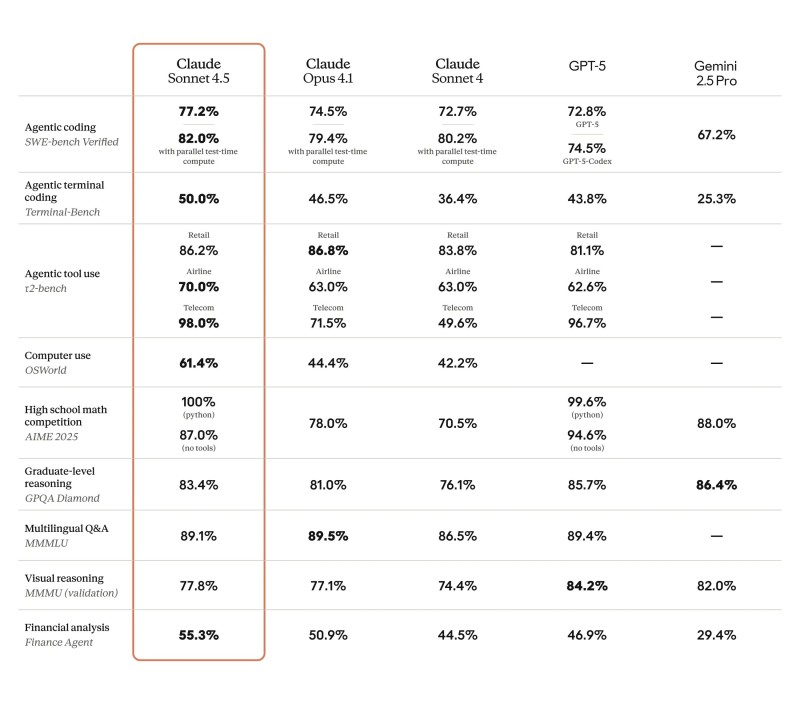
AI observer 今井翔太 / Shota Imai@える dropped the latest numbers, and they're revealing. Claude 4.5 Sonnet hit 82% on SWE-bench Verified, a brutal 500-task coding test using parallel compute. That beat the competition. In financial reasoning, it wasn't even close—Claude scored 55.3% while GPT-5 managed 46.9% and Gemini 2.5 Pro limped in at 29.4%.
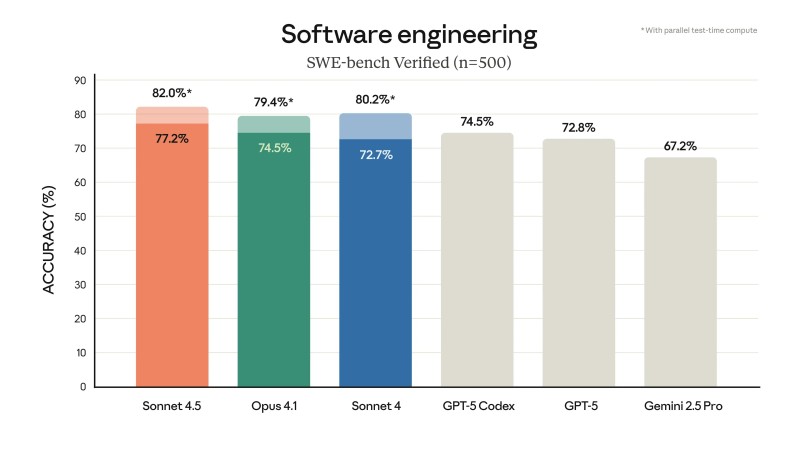
But the coding benchmark tells a more interesting story. Claude 4.5 edged out GPT-5 Codex, but with a catch—Claude used parallel test-time compute while GPT-5 didn't. Level the playing field and who knows what happens? This is where methodology matters as much as raw scores.
Key Performance Metrics:
- Tool Use: Claude 4.5 dominated telecom tasks (98%) and retail (86.2%), narrowly beating GPT-5's 81.1%
- Graduate Reasoning: GPT-5 held the edge at 85.7% versus Claude's 83.4% on GPQA Diamond
- Multilingual Tasks: Dead heat—both models scored around 89% on MMLU
- Math Competitions: Claude hit perfect 100% on Python math tasks, GPT-5 scored 99.6%
Where Each Model Shines
The pattern is clear: no model owns everything. Claude excels at structured tasks and safety. GPT-5 brings raw reasoning power and flexibility. Users are already adapting—they're picking Claude for financial work and safer outputs, then switching to GPT-5 for complex coding and research.
This is the new reality. Developers aren't loyal to one model anymore. They're using whichever tool fits the job. Claude 4.5 might have the edge in specific benchmarks, but GPT-5's versatility and user base keep it in the fight. And with Gemini lurking in third, the competition isn't going anywhere.
 Peter Smith
Peter Smith


