 Usman Salis
Usman Salis

Large language models like GPT-4, Claude, and Gemini are everywhere now - helping us write, code, and solve problems. But here's the thing: as these AI systems become more important in our daily lives, we need solid ways to figure out which ones actually work well.
Why Getting Evaluation Right Matters
Recently, Dhanian shared a great breakdown of how experts evaluate these models, covering everything from technical metrics like Perplexity and BLEU scores to good old-fashioned human testing. It's not just about building powerful AI - it's about making sure it's reliable.
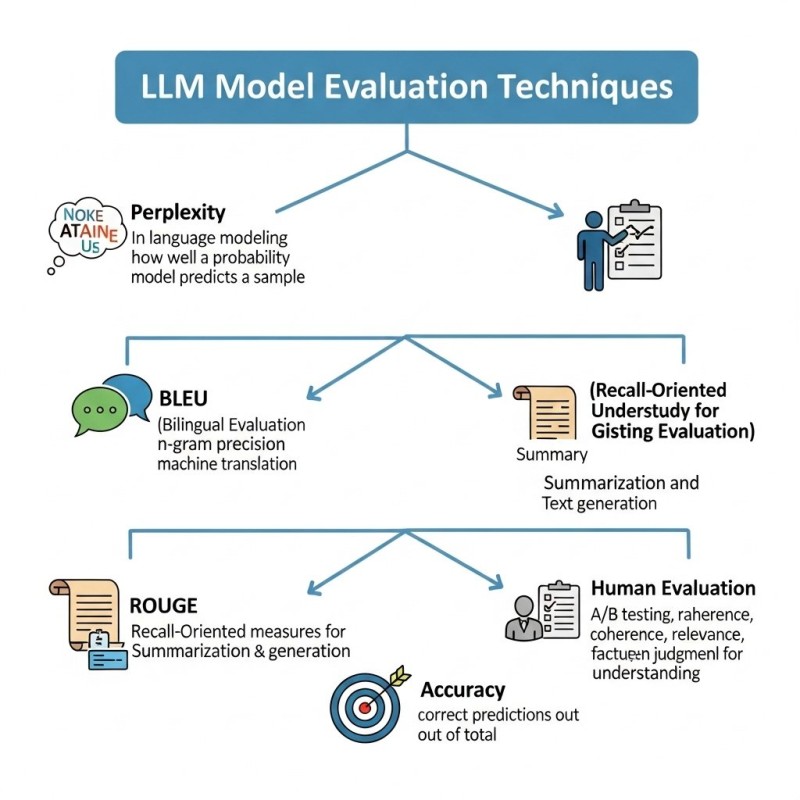
Building a smart model is only step one. Testing it properly tells us if it's actually useful in the real world. Good evaluation helps developers compare different models, spot weaknesses before they become problems, and ensure the AI is not just accurate but also safe and helpful. Without this, you end up with models that look great on paper but fall apart when people actually use them.
The Main Ways We Test LLMs
Perplexity measures how well a model predicts the next word in a sentence. Think of it like testing if someone can finish your sentences - lower scores mean the AI "gets" language patterns better. It's a solid technical measure but doesn't tell you if the output is actually useful.
BLEU is the go-to metric for translation tasks. It compares the AI's output to human-written examples, looking at how many word sequences match up. So "I love pizza" versus "I enjoy pizza" would get partial credit. It's precise but sometimes misses the bigger picture when different words mean the same thing.
ROUGE focuses on summarization and checks whether the AI captured the key information from the original text. If important details get lost in the summary, the ROUGE score drops. It's particularly useful for news summaries and document condensation.
Accuracy is straightforward - what percentage of answers did the model get right? It works great for clear-cut tasks like determining if a movie review is positive or negative, but struggles with more nuanced situations.
Human Evaluation remains the gold standard. Real people judge whether responses are helpful, safe, and well-written. This often involves A/B testing where humans compare different AI outputs side by side. It's expensive and time-consuming, but it's the only way to know if AI actually meets human expectations and values.
Why This Mix Matters for AI's Future
The smart approach combines both automated testing for speed and scale with human judgment for quality and nuance. As LLMs move into sensitive areas like healthcare and finance, evaluation needs to get even more sophisticated. We're likely heading toward hybrid systems that use quick automated checks followed by deeper human review for critical applications.
 Usman Salis
Usman Salis


