 Saad Ullah
Saad Ullah

Anthropic's Claude Sonnet 4.5 has completed its latest benchmark tests, showing both progress and areas where competitors maintain an edge. While the model demonstrates improvements over earlier versions, its performance in conversation and reasoning tests reveals the AI race remains intensely competitive.
A Tweet Sparks Debate
When Lisan al Gaib shared benchmark results showing Claude Sonnet 4.5 in sixth place on MultiChallenge (multi-turn conversations) and fifth on Enigma (puzzle-solving), calling the results "a bit disappointing," it triggered widespread discussion across the AI community about whether the model lived up to expectations.
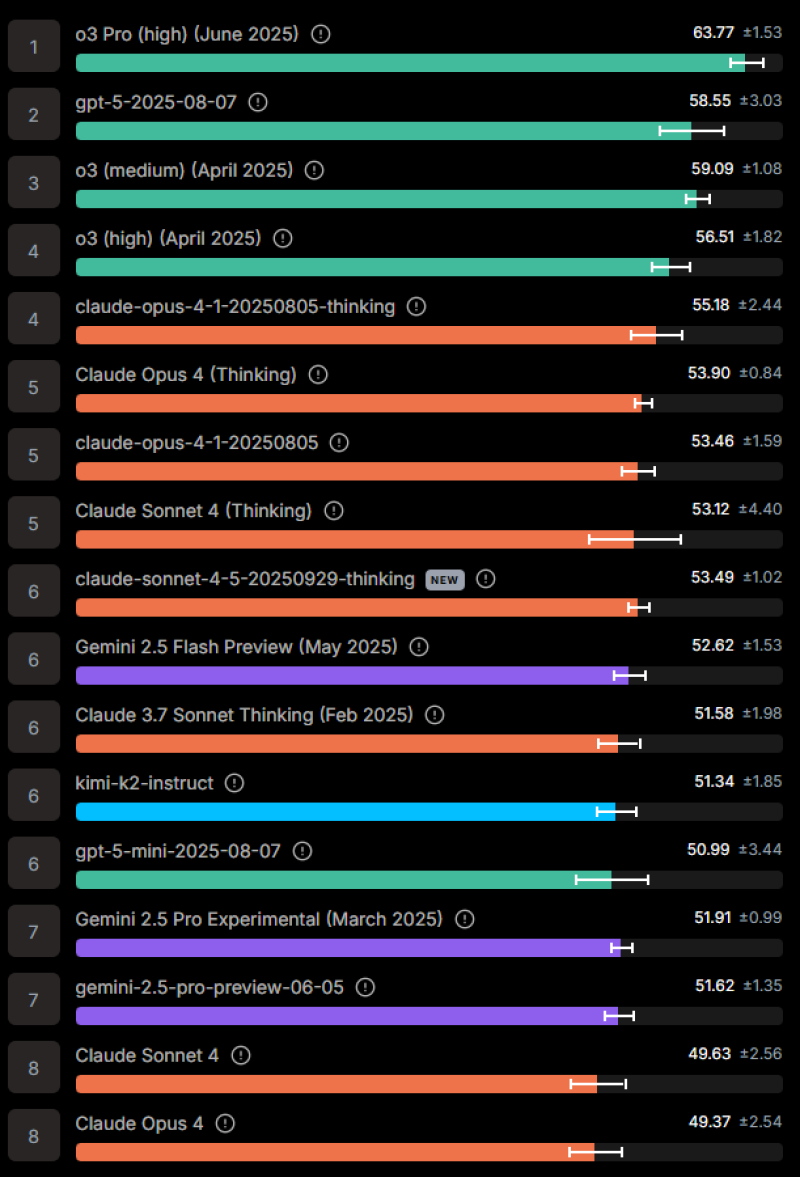
OpenAI's o3 Pro leads with 63.77, followed by GPT-5 at 58.55. Claude Sonnet 4.5 scored 53.49, placing it mid-tier. In MultiChallenge, it landed sixth, showing competitive conversational abilities. On Enigma, the fifth-place ranking demonstrates improved reasoning, though still trailing OpenAI's o3 and GPT-5 series.
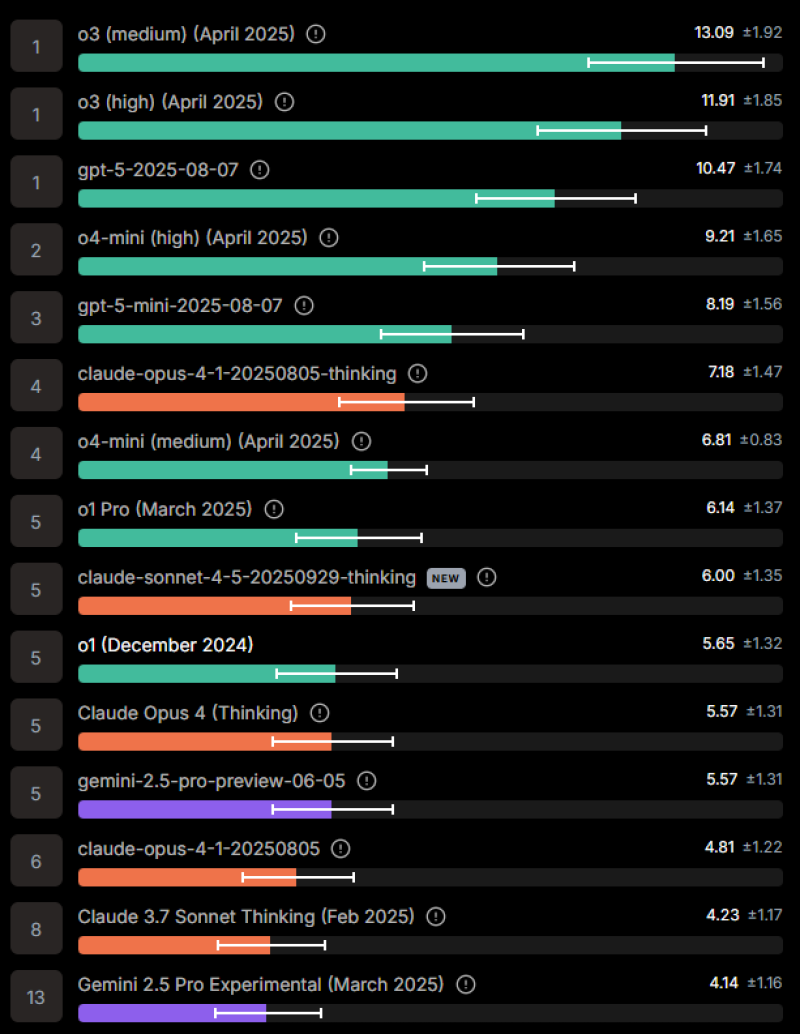
Why It Matters
The competition has intensified with OpenAI's rapid rollout raising the bar. Still, Anthropic continues making steady progress, keeping Claude firmly among serious contenders. But benchmark scores only tell part of the story—real-world success depends equally on safety, reliability, and practical integration. Claude's reputation for thoughtful, careful responses might matter more in practice than leaderboard positions.
These results suggest Claude Sonnet 4.5 is a credible player, even if not topping benchmarks. Anthropic's focus on Constitutional AI and alignment could prove particularly valuable where businesses prioritize trustworthy AI alongside performance. As major players push boundaries, the conversation is shifting from who posts the highest scores to who can deliver practical, safe, and cost-effective systems at scale.
 Saad Ullah
Saad Ullah


